Elasticsearch is the most popular RESTful search engine out there, and for a good reason. It's fast, versatile, and has evolved a lot from the recipe search engine that it once was.
Chances are, you've used it today. If you search on Wikipedia, the suggestions are generated in part via Elasticsearch. When you book a ride or a meal through Uber, Elasticsearch is used to enhance your user experience. As you watch Sky Sports, Elasticsearch works behind the curtains to ensure that the video stream doesn't pause just as your favorite team is about to score.
Spatialized deploys Elasticsearch to help businesses make data-driven decisions at the speed of thought.
Part I: Business Intelligence ReportingThe ChallengesThe ProcessSo far so good but there's a catchThere's one more issue — nested aggregations The ImpactThe Next Steps
Part I: Business Intelligence Reporting
The Challenges
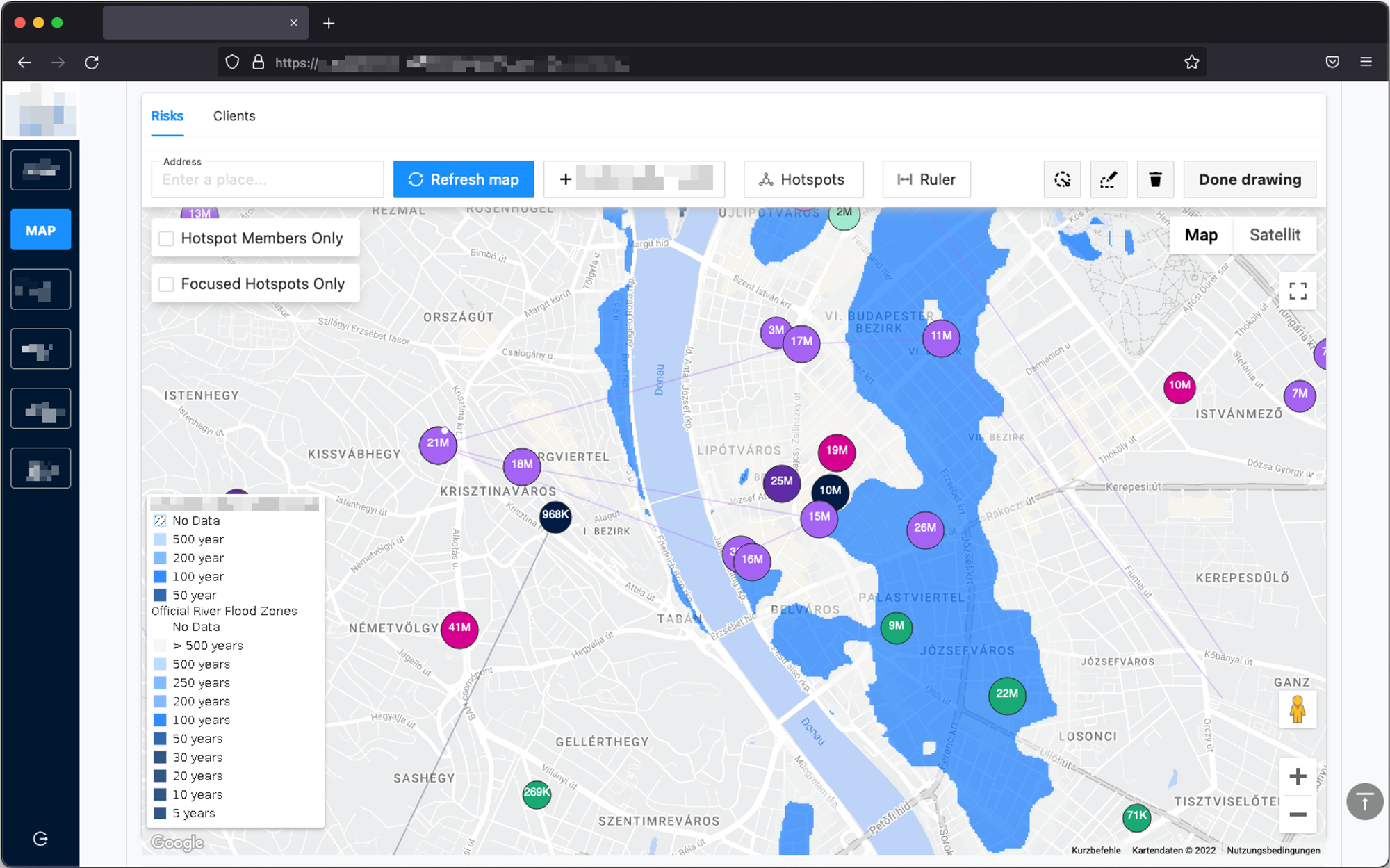
A major insurance player in CEE approached us with the aim to:
- analyze their corporate client portfolio from a bird's eye view
- identify non-trivial, high-risk geospatial clusters
- and make well informed, strategic decisions moving forward.
We took up the challenge.
The target audiences range from underwriters, through risk engineers, all the way to regional stakeholders. These people are well-versed at what they do and know the structure of the underlying contractual data by heart. But they needed a platform to slice and dice the data in a standardized manner — esp. when it came to unified, cross-border reporting.
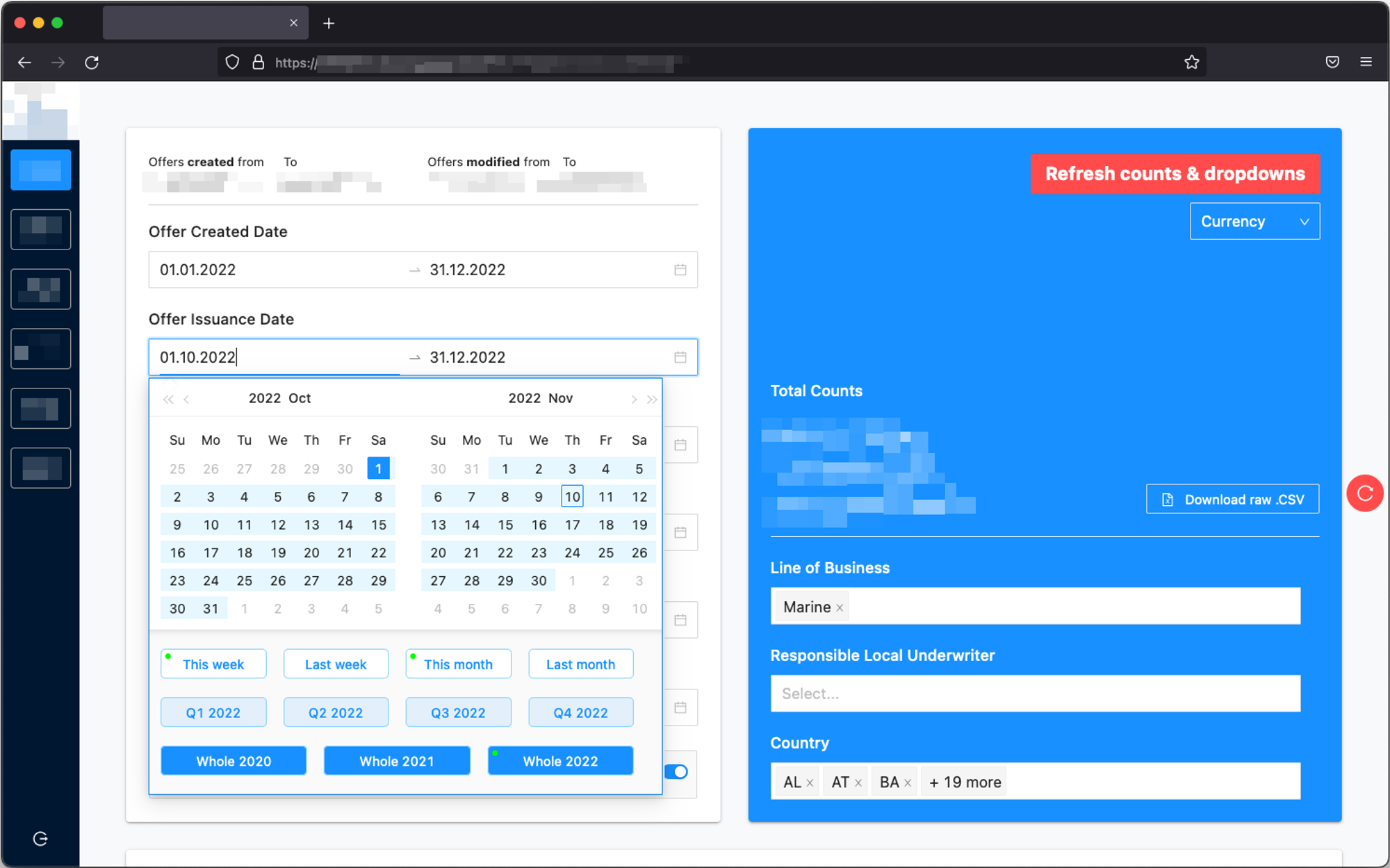
The Process
Our client's data was spread across dozens of SQL tables. Our proposed Elasticsearch cluster would merge, normalize, and shard the data to optimize for fast and efficient lookups.
Now, Elasticsearch is a NoSQL datastore that doesn't support query-time table joins. As such, it expects the incoming documents to be flattened and contain all the necessary information at ingest time.
That said, if there's a
customer record in SQL and this customer has signed multiple insurance contracts (typically renewed on a yearly basis), the customer attributes need to be duplicated in each contract record. Since the customer's general attributes (company id, name, address, turnover, etc.) don't frequently change, the duplication and eventual updates are manageable. Having to deal with an increased storage footprint is acceptable too.Now comes the fun part. See, a
property contract could cover one or more locations. The parent contract then typically contains the status, sum insured, premium, and so on.
But so do the individual locations — every warehouse, production facility, and industrial site is assessed differently based on the geo-risks (perils) involved. These perils are themselves a group of key-value pairs.In essence, a redacted and condensed
contract document looks like this:{ "id": "...", "created_at": "2020-02-03 08:50:00", "policy_issued_at": "2020-03-01 00:00:00", "client": { "name": "An Energy Utility Company", "turnover_EUR": 1000000000 }, "sum_insured_EUR": 2000000, "premium_EUR": 178000, "locations": [ { "id": "...", "address": { "geo_point": [ -74.0062, 40.7128 ] }, "sum_insured_EUR": 7000000, "premium_EUR": 48500, "perils": { "flexa": 7.8, "storm": 5.4, "machinery_breakdown": 3.9 } }, { "id": "...", "address": { "geo_point": [ -82.0034, 39.2247 ] }, "sum_insured_EUR": 13000000, "premium_EUR": 129500, "perils": { "flexa": 7.2, "storm": 4.4, "machinery_breakdown": 3.9 } } ] }
So far so good but there's a catch
There's no dedicated
array type in Elasticsearch:Elasticsearch has no concept of inner objects. Therefore, it flattens object hierarchies into a simple list of field names and values. [source]
As such, the document above would be internally transformed into something like:
{ ... "locations.sum_insured_EUR": [ 7000000, 13000000 ], "locations.premium_EUR": [ 48500, 129500 ] ... }
The associations between the
sum_insured and premium would be lost. { "mappings" : { "properties" : { ... "locations" : { "type": "nested", <--- "properties" : { "address" : { ... }
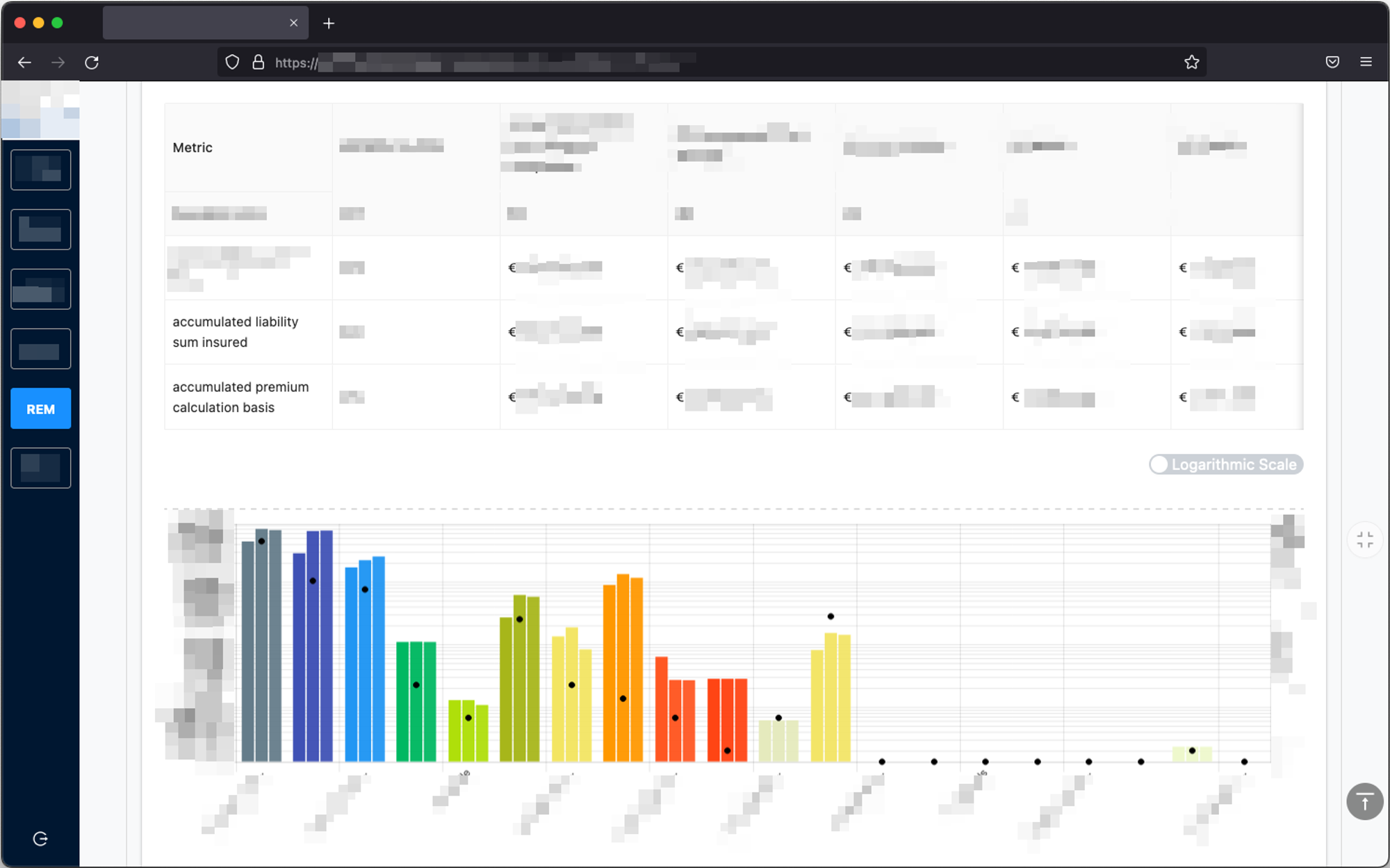
Nested fields function as standalone subdocuments and keep the relations intact.
When the relations are intact, the resulting statistical analysis is consistent:
There's one more issue — nested aggregations
If we wanted to calculate, say, the average peril assessment value, the current setup wouldn't allow it. Elasticsearch doesn't support wildcard aggregation paths and so the query below would fail because there's no singular field to target:
POST contracts-index/_search { "aggs": { "avg_peril_risk_class": { "avg": { "field": "locations.perils.???" <--- } } } }
We therefore chose to restructure the peril attributes into a nested array of objects:
{ "locations": [ { "perils": [ { "name": "flexa", "risk_class": 7.8 }, { "name": "storm", "risk_class": 5.4 }, { "name": "machinery_breakdown", "risk_class": 3.9 } ] }, ... ] }
The query thus became:
{ "aggs": { "nested_peril_context": { "nested": { "path": "locations.perils" }, "aggs": { "avg_peril_risk_class": { "field": "locations.perils.risk_class" } } } } }
which perfectly supports highly granular filtering, allowing us to display deduplicated dropdown options:
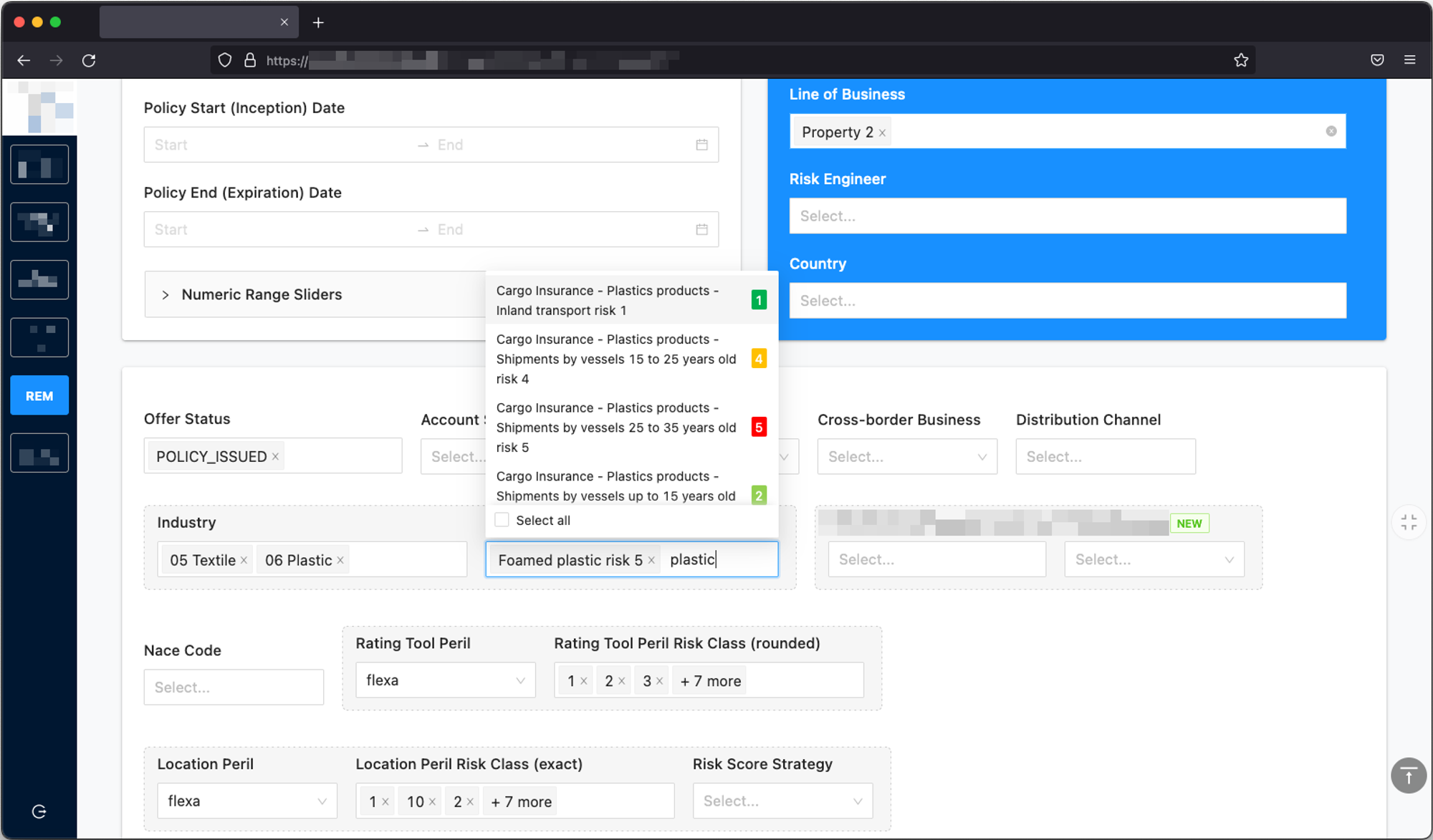
The stakeholders can now freely slice and dice their portfolio. As a bonus, they can now easily identify data quality issues, which, when addressed, improve the accuracy of their reports.
The Impact
Two years and a few dozen iterations later we arrived at a stable document structure which, with the help of Elasticsearch, enables stakeholders to answer questions like:
- Which country in my portfolio had the lowest premium vs. sum insured ratio last year?
- Which high-risk, low-premium locations are dangerously close to one another (= forming an exposure cluster)?
- Which underwriters improved their performance year-over-year?
- Who are the top 3 business partners of the current quarter?
- and so many more…
At the end of the day, the filter combinations are virtually endless.
Each stakeholder can mine for insights relevant to them at the speed of thought.
The Next Steps
Our insuretech business intelligence web application is a work-in-progress. It's being extended, course-corrected, and gradually deployed to more and more client regions.
There are ongoing discussions about bringing more historical data in. On the other side of the spectrum, there's the aspect of introducing real-time alerting, esp. in connection with natural disasters. Exciting new challenges lie ahead of us.
On the other hand, there's limited playroom for predictive analytics. Just like the weather, risk is notoriously hard (if not downright impossible) to predict! That said, we'd rather squeeze as much insight out of the large trove of existing client data before moving into the "fortune telling" business.
One principle remains constant — garbage in, garbage out. Our shiny applications would bring little value when the underlying data is unreliable, incomplete, or erroneous. Elasticsearch certainly cannot "fix" the data. It can, however, prominently point the outliers out … and do so incredibly fast.
Spatialized s.r.o.
hello@spatialized.io
spatialized.io